
How to Build a Simple, Bulletproof Data Pipeline
By Bruno Masciarelli
In most organizations, a lot of value can be delivered with a setup that avoids high costs and unnecessary complexity. The most common scenario is not real-time streaming or exotic architectures. It is daily extraction from one or more transactional systems backed by a relational database.
Despite how common this scenario is, many pipelines fail for reasons that have little to do with technology. They fail because of fragile assumptions, premature optimization, or the introduction of complexity before it is actually needed.
In this article, I want to walk through a simple but realistic example and show how a few design decisions, even when they look basic, can make a meaningful difference in robustness, operability, and long-term maintainability.
The Scenario
Consider a platform where users create accounts to produce content, which is later consumed by other users. This is a pattern that shows up everywhere: publishing platforms, learning platforms, internal knowledge bases, and even some SaaS products.
A minimal OLTP model includes:
* Accounts
* Contents
* Content attributes
* Consumption events
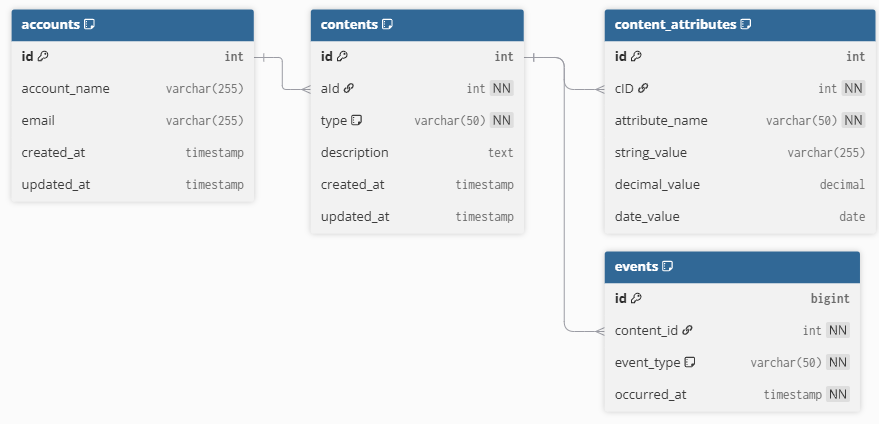
In this scenario, the transactional model includes a content_attributes table that follows an entity-attribute-value (EAV) pattern. Instead of storing attributes as columns, each attribute is stored as a separate row, identified by its name and value.
As a result, a single content record is represented by multiple rows in the attributes table: one for its category, another for its rating, and potentially many more. This type of modeling is common in systems where flexibility is prioritized and the set of attributes changes frequently, such as CRMs and e-commerce platforms.
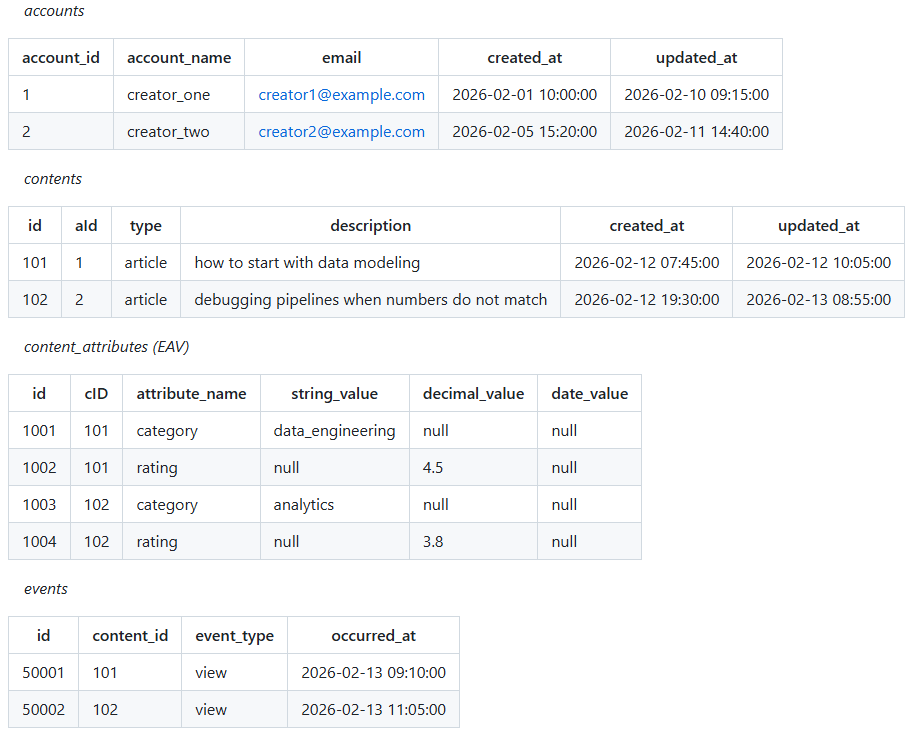
Any data initiative should start from a business problem. Suppose the business needs to know which content categories are generated the most and which are consumed the most. That is one of the questions we want to answer with this setup.
Let’s see how to solve this using a layered architecture.
Infrastructure Assumptions
If there are no regulatory constraints, running everything in the cloud simplifies operations significantly. Fewer moving parts, fewer operational dependencies, and fewer things that can silently break, especially when serverless services let you focus on data movement instead of infrastructure babysitting.
If the source database lives on-premises, a VPN connection is usually enough to support daily extraction. You do not need a sophisticated integration layer to reliably move data once per day.
The goal at this stage is not to optimize costs or latency. It is to create a setup that is predictable and easy to reason about.
Architecture in Layers
The architecture is organized into three layers: raw, intermediate, and analytics. You can call them bronze, silver, and gold, or anything else. The names do not matter. The separation of responsibilities does.
Each layer exists to solve a different type of problem.

Raw Layer
The raw layer stores data exactly as it comes from the source. No casting, no cleaning, no business logic. All fields are represented as strings. The goal is simple: do not lose information.
This layer is often underestimated. Trying to “fix” data too early usually makes debugging harder, not easier. When something looks wrong downstream, having access to the original, untouched data is critical.
Catalogs and Master Data
For catalogs and master data, typically ranging from thousands to millions of records and subject to updates, full extraction and append into object storage using a columnar format like Parquet can be a reasonable trade-off when reproducibility matters more than minimizing storage.
There was a point where this became very clear to me. Years ago I inherited a pipeline that relied on incremental extractions based on an updated_at field. On paper, it looked reasonable. In reality, developers were occasionally applying manual updates directly in the database, and those changes were not always reflected in that column. Records were silently skipped. I spent weeks debugging transformations and checking joins, convinced the problem was in my code, until it became obvious that the issue was upstream. The pipeline was doing exactly what it was told to do, just not what we needed.
Since then, I am comfortable paying the storage cost of full loads if that gives me reproducibility and removes a fragile dependency on update timestamps.
In many simple daily batch scenarios, introducing Iceberg or Delta too early can add operational and conceptual complexity before it is needed. They are powerful frameworks, but they also add operational and conceptual complexity. In many cases, that complexity does not pay off this early in the pipeline.
Events
Events are a different case. Here we usually deal with hundreds of millions or billions of records, and the assumption is that events do not change after they are written. If that assumption is true, it should be explicit. Ideally, someone should be willing to sign it in blood.
When CDC is available and reliable, it is the best option. If not, incremental extraction based on timestamps is acceptable, as long as the immutability assumption is clear and enforced. If events can be updated, then they are not really events, and the design needs to be reconsidered.
Intermediate Layer
The intermediate layer is where data starts to become usable.
This is where cleaning, type casting, and renaming happen. Types are fixed. Column names are normalized. Obvious inconsistencies are handled.
I have found the dbt idea of staging models, one per source table, extremely useful, even outside of dbt itself. Having a clear, isolated model per source table makes the inevitable detective work much easier when a number does not add up.
And in real projects, detective work always happens.
A very common example involves duplicated entity identifiers. Suppose the accounts table contains duplicate account_id values due to bad upstream data or manual fixes in the source system. If accounts and contents are joined too early, each duplicate account row multiplies the associated contents. Suddenly, content counts are higher than expected, and it is not obvious why.
When this happens in a wide, already-joined table, debugging is painful. You have to identify where the duplication was introduced and trace it back across transformations. In contrast, when each source has its own cleaned representation in the intermediate layer, the issue becomes trivial to spot. You can detect the duplicate accounts directly, fix or deduplicate them there, and only then perform the join. This is precisely the kind of problem the intermediate layer exists to handle: isolating and resolving data quality issues before they propagate downstream.
Dealing with EAV models
EAV models work well for transactional systems, but they introduce friction when data is used for analysis. Simple questions like “what category does this content belong to?” are no longer a direct column lookup. They require filtering by attribute name, selecting the correct value column, and often pivoting multiple rows back into a single logical record.
In practice, this complexity leaks into every downstream query unless it is handled explicitly. This is why EAV attributes are usually flattened in the intermediate layer into a wide, typed representation that can be reasoned about and joined safely.
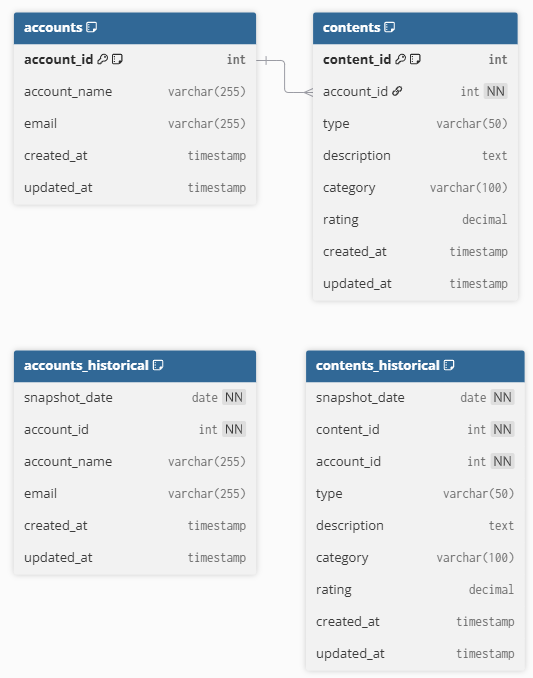
In the intermediate layer, I consolidate those attributes into a single wide content table. In this example, attributes like category and rating become explicit, typed columns. This does not mean the EAV model was a mistake. It simply means it is not the right shape for analytics.
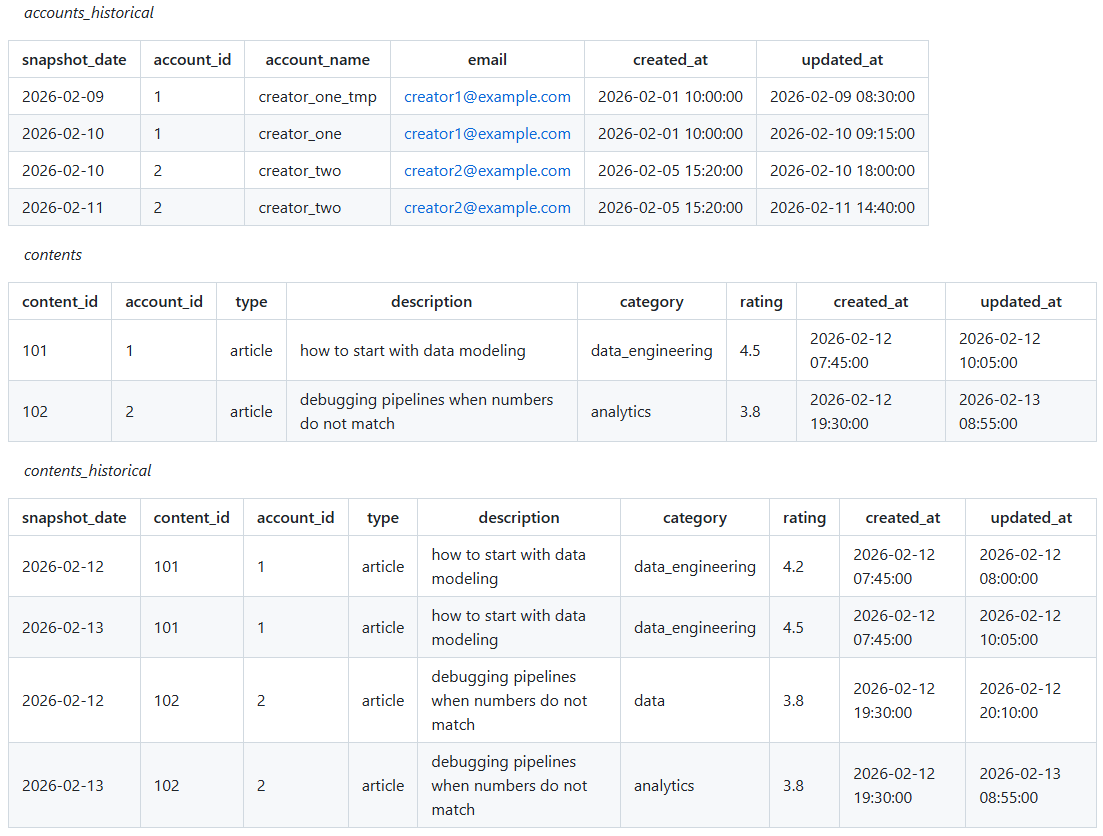
Current vs Historical State
Another useful pattern in the intermediate layer is maintaining two structures:
* A table with the current version of each entity
* A historical table with daily snapshots, for example with 30 days of retention
In practice, most analyses rely on the latest available state. Forcing every query to scan a large historical table, even when it is partitioned, adds compute cost with little benefit.
Having both options allows you to choose the right trade-off depending on the use case, without complicating downstream models.
Analytics Layer
The analytics layer is where data is shaped for consumption.
For this problem, dimensional models are sufficient. Facts for content consumption, dimensions for contents, and accounts. There is no need to reinvent patterns that have been working for decades.
Explicit column naming may look verbose, but it avoids real problems. When multiple dimensions expose fields like created_at or name, many BI tools collapse them into a single namespace. Prefixing columns with the entity name makes it immediately clear what each field represents and prevents subtle, hard-to-detect mistakes in analysis.
Slowly Changing Dimensions, In Practice
Slowly changing dimensions type 2 is a useful technique, and in this model, I do use a type 2 dim_contents.
In practice, business users tend to get confused by surrogate keys, validity ranges, and multiple versions of what looks like the same entity. Even technically strong users make mistakes when they have to reason about time validity in every query.
For that reason, I keep the SCD2 logic in the model, but expose a simplified view on top of it. Joins are already resolved. Only the columns that make sense for analysis are visible. Validity ranges and surrogate keys stay hidden.
This approach preserves historical correctness without forcing every consumer to understand how it works internally.
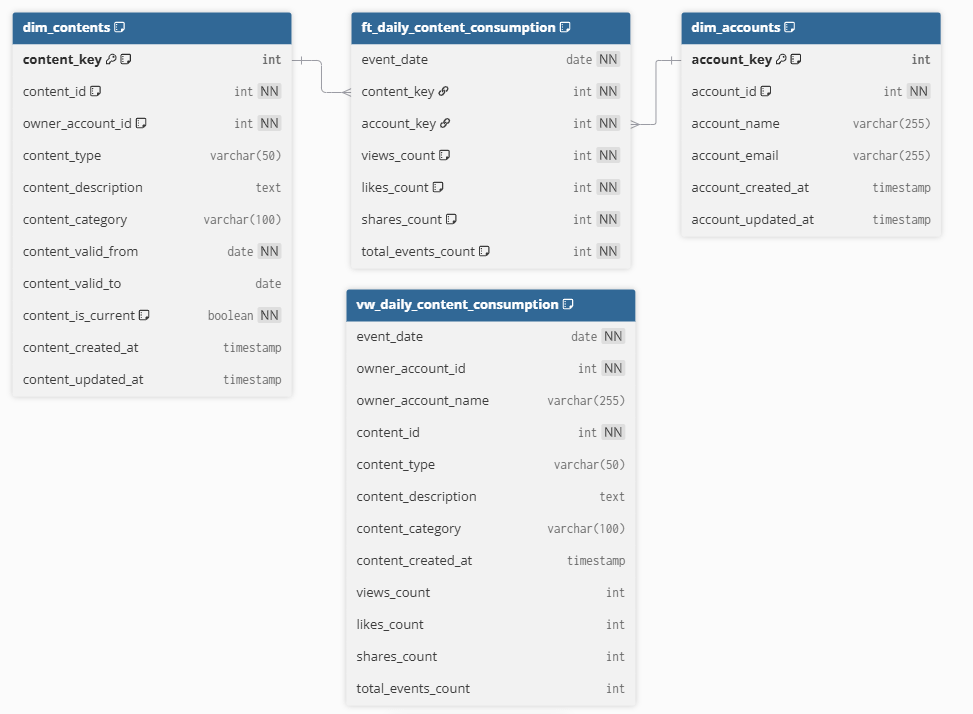
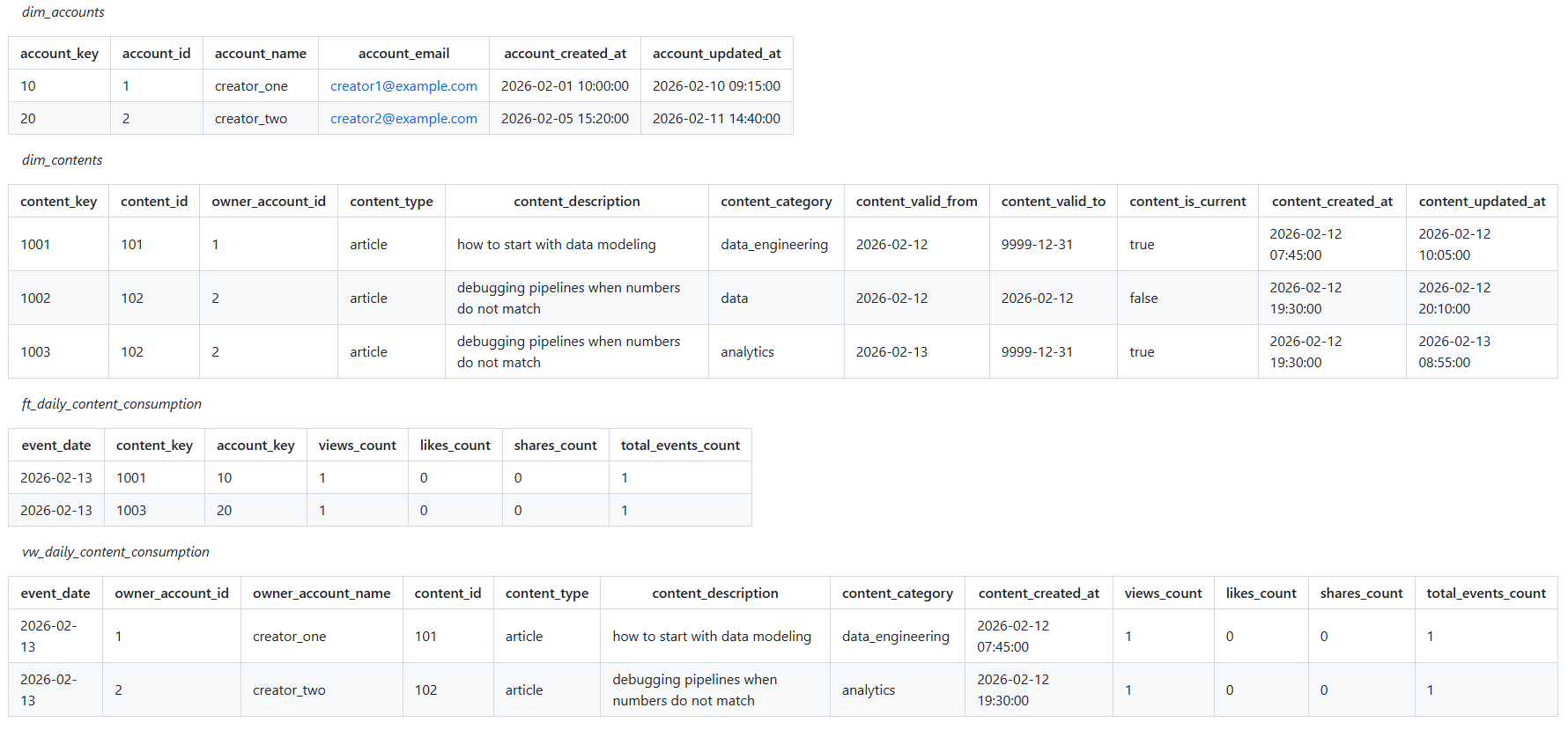
With the analytical layer in place, answering the business question no longer requires understanding the underlying model. The view exposes content categories and consumption metrics directly, allowing the analysis to focus on the question rather than on the mechanics of the data:
SELECT
content_category,
SUM(total_events_count) AS total_consumption
FROM vw_daily_content_consumption
GROUP BY content_category
ORDER BY total_consumption DESC;
Why This Works
The best pipeline is the one you don’t have to think about. And you get there not by being clever, but by being deliberate.
Most pipelines don’t fail because of scale or lack of advanced tooling. They fail because they rely on fragile assumptions, engineers try to optimize too early, or expose unnecessary complexity to the people consuming the data.
This setup prioritizes:
* Reproducibility over cleverness.
* Simplicity over novelty.
* Operational stability over theoretical elegance.
In practice, that is often what makes the difference between a pipeline that quietly works every day and one that constantly needs attention.
Author Bio
Bruno Masciarelli is a data architect with over 10 years of experience designing and building analytical solutions.
Author’s Note
This article was originally written and shared before Bruno joined his current employer. The views expressed are personal and do not represent his employer.
It’s a very well written article. Plus 1000 to keeping a simple data pipeline that’s intended to solve business problem rather than building a complex solution that stakeholders lose trust eventually